Handling Factors in Formulas
Currently, two Tools on mightymetrika.com handle factors (we can also call factors categorical variables) in a way which is likely to cause confusion
Keep in mind that this post pertains to using formulas within the 'shiny' web-applications. When using 'mmirestriktor', 'mmibain', 'restriktor', or 'bain', users can handle factors in the regular R fashion before fitting statistical models.
The Factor Issue
Consider these two csv files:
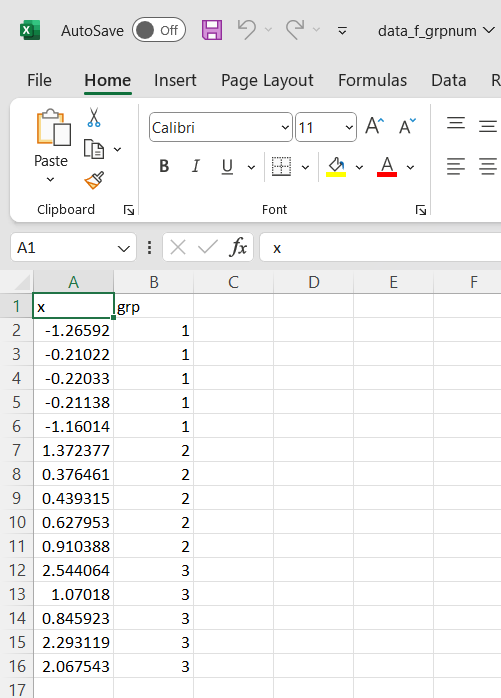
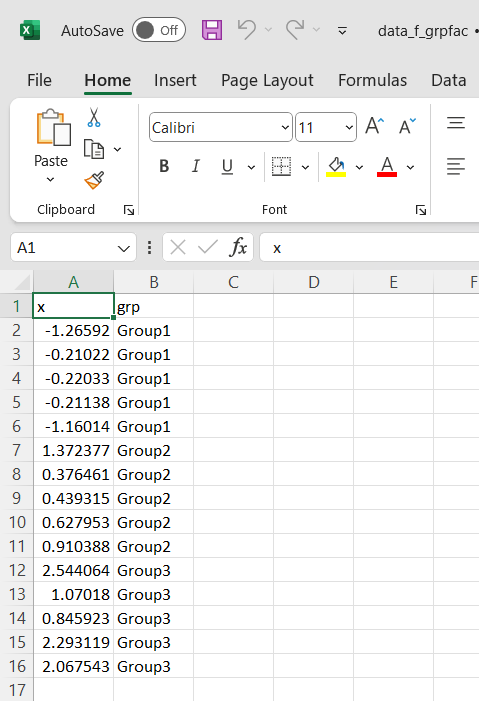
When processing the csv on the left (data_f_grpnum) the grp variable will typically get treated as a numeric variable. On the other hand, when working with the csv on the right (data_f_grpfac) the grp variable will get treated as a factor.
When uploading a csv file for mightymetrika.com 'shiny' applications, you should make sure that variables that you want treated as factors cannot be automatically parsed as numeric. Put another way, make sure your factor variables include letters in their values.
For the csv files above, we force our grp variable to behave as a factor by prefixing the values with "Group". Any letter would achieve the same goal.
What Happens When We Read a Factor as Numeric?
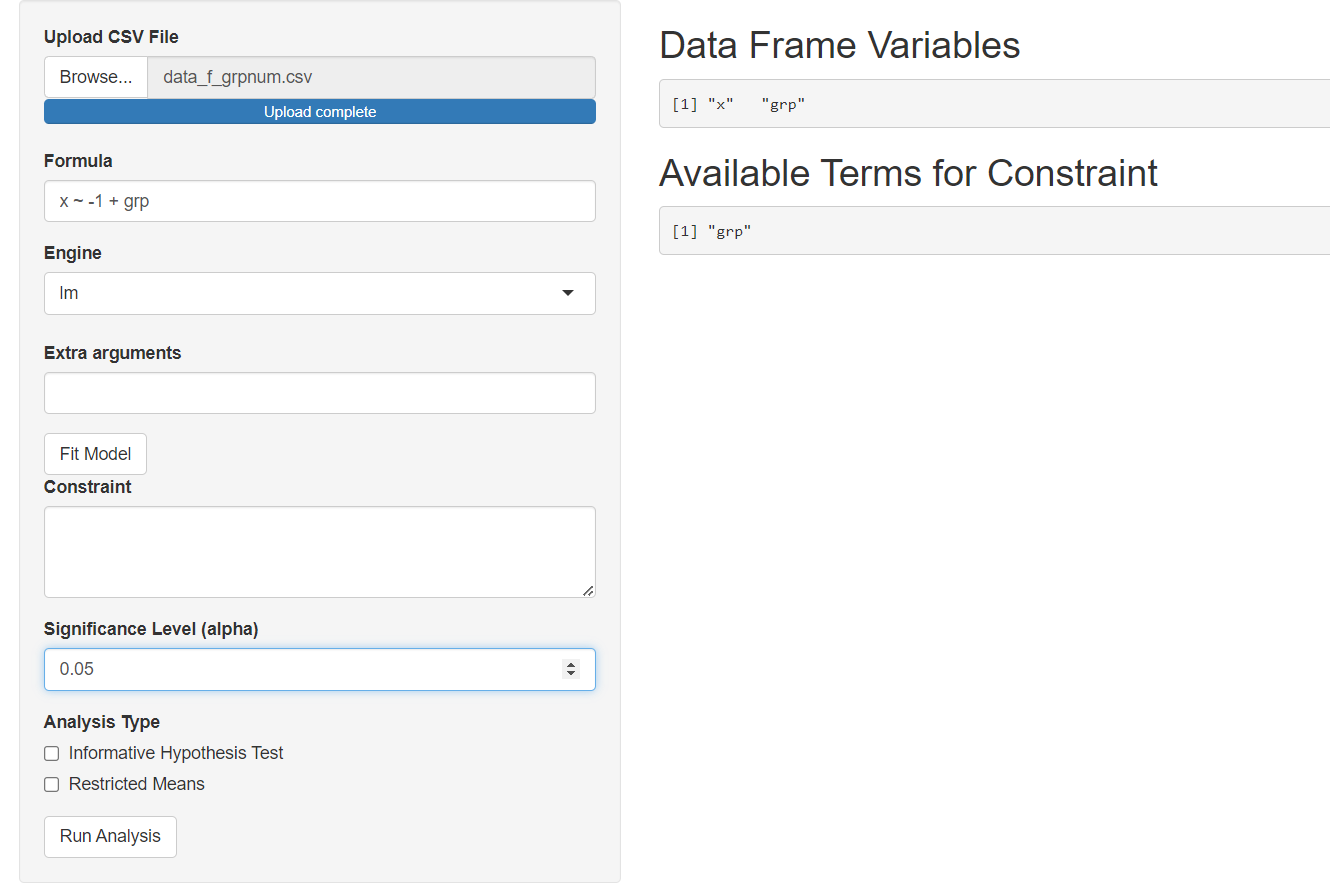
Let's see what happens when we accidently try to run the mmirestriktor app on the data_f_grpnum.csv file when we want the grp variable to function as a categorical variable (i.e., a factor).
In the example below, we start by:
- Read in the data_f_grpnum.csv file
- Notice that the available variables are 'x' & 'grp'
- Set up the formula x ~ -1 + grp
Up to this point, everything looks as expected. However, after we fit the model we see that the Available Terms for Constraint only shows the variable 'grp'. However, since we wanted the grp variable to at as a categorical variable, we wanted the available terms to show us something that corresponds to the groups. Since the "terms" (i.e., grp) are not consistent with the goal (comparing groups or another goal that would inspire use to use a categorical variable), we know that something has gone horribly wrong.
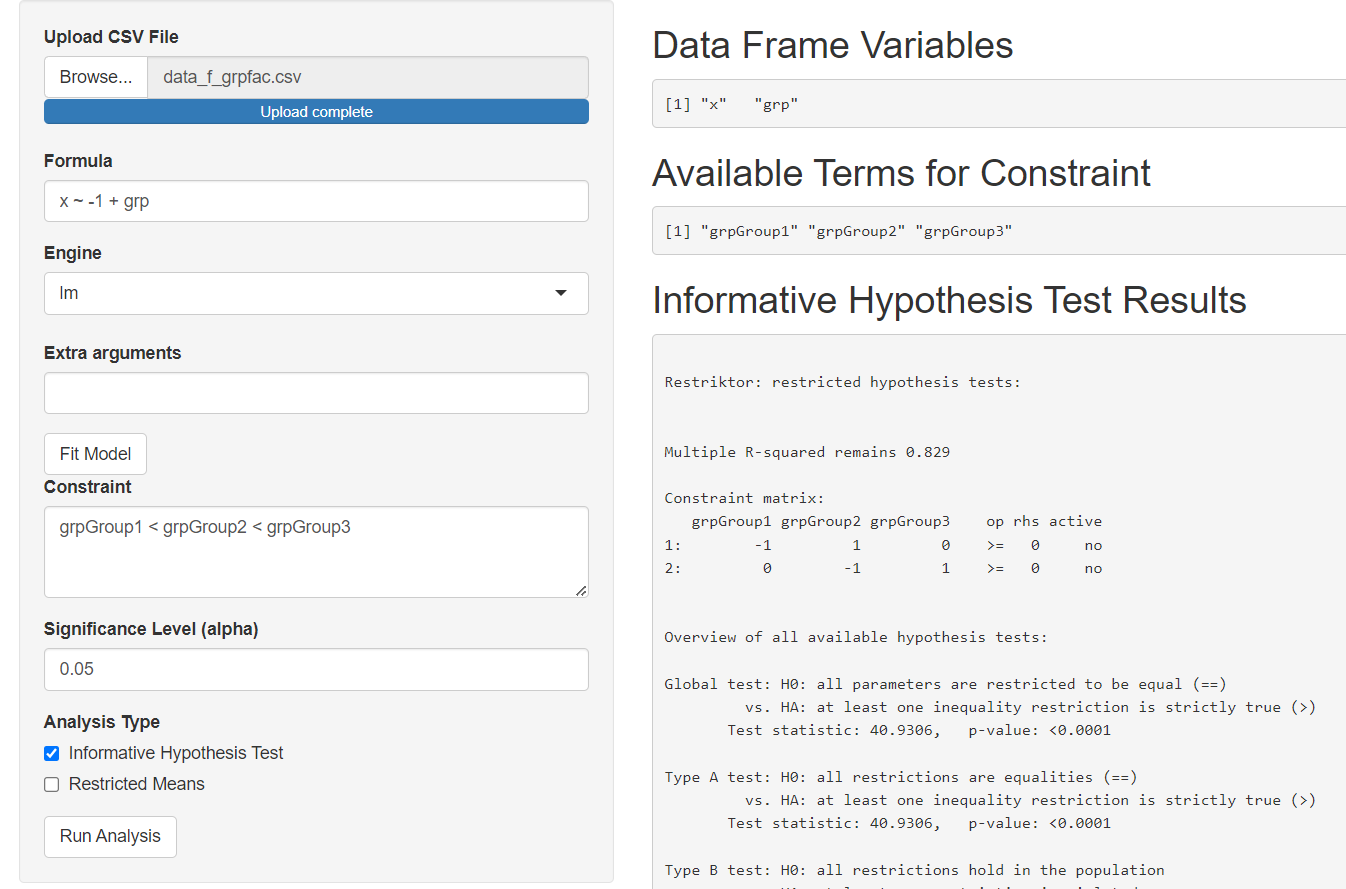
What Happens When We Read a Factor as Factor?
Now since we know we want the grp variable to function as a categorical variable, we run the mmirestriktor app on the data_f_grpfac.csv and we get the following Available Terms for Constraint.
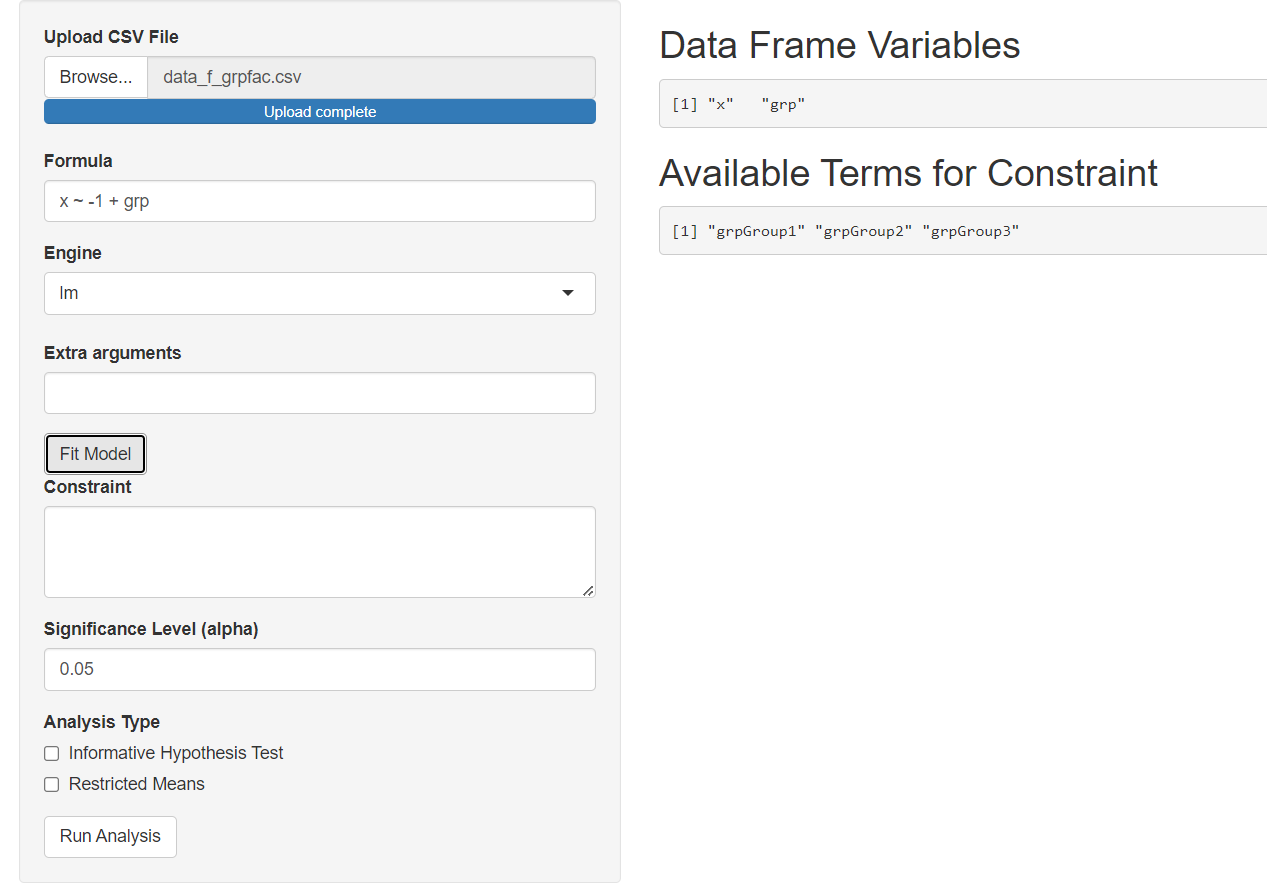
Now we can use the information in the Available Terms for Constraint to specify a constraint which compares the groups in our 'grp' variable and then we can run an Informative Hypothesis Test analysis.