npboottprmFBar Release Party
The 'npboottprmFBar' package is now available on CRAN. The name, stands for the nonparametric bootstrap test with pooled resampling method (npbp) via the FBar distribution. The goal is to combine two methods:
- The nonparametric bootstrap test with pooled resampling method
- Method: Dwivedi et al 2017
- R package: npboottprm
- Informative hypothesis testing for linear models
- Method: Vanbrabant & Rosseel 2020
- R package: restriktor
In Dwivedi et al 2007, the npbp is impemented for the independent sample t-test, the paired t-test, and the F-test; on the other hand, the npboottprmFBar package adapts the npbp to work with the Fbar statistic (as implemented in 'restriktor') rather than the usual F statistic used in ANOVA.
Unlike most Mighty Metrika packages released on CRAN, npboottprmFBar does not (yet) have an associated 'shiny' application. This is because I want to get a better understanding of how the method functions. As such, the npboottprmFBar::persimon() function can be used to run simulations which fill out table shells similar to Dwivedi et al 2017 tables S2 and S3 (see snippets below) which focus on Type I error and statistical power. These simulations will be able to compare the performance of the npboottprmFBar method to the methods already present in the aforementioned tables S2 and S3 as well as to the restriktor::iht() default method and restriktor::iht() with boot = "parametric".
Snippets of Table S2 and Table S3 from Dwivedi et al 2017
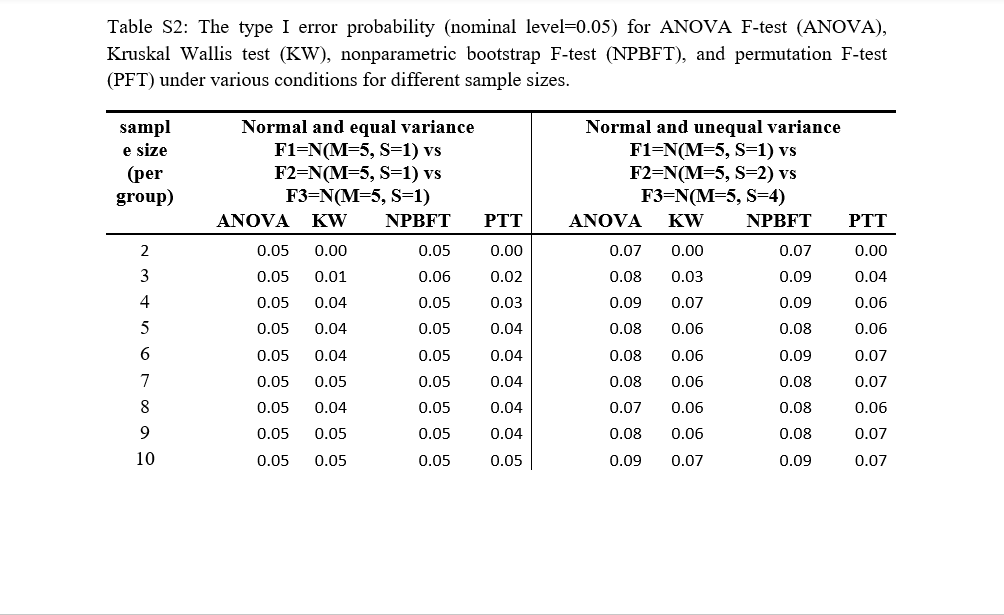
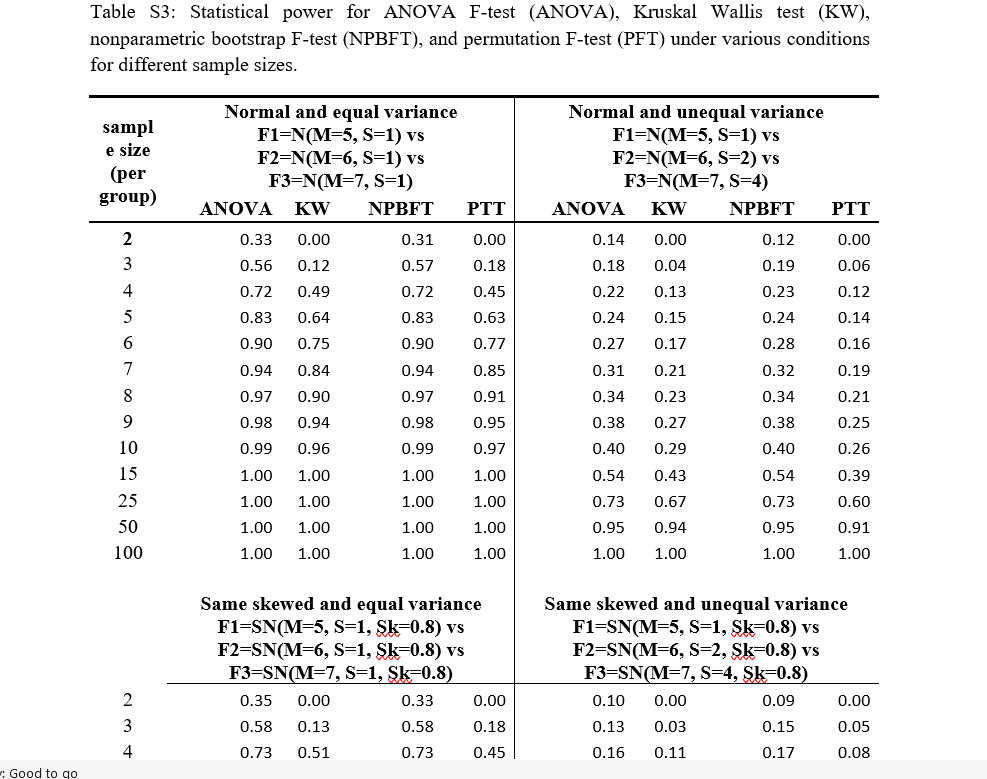
In the npboottprmFBar "persimon" simulations (performance simulation on type I error or statistical power), all of the methods associated with informative hypothesis testing will be run under three different constraint scenarios:
- 0 inequality constraints (grp 1 = grp2 = grp3)
- 1 inequality constraints (grp1 < grp3)
- 2 inequality constraints (grp1 < grp2 < grp3)
Another caveat is that for each model in the simulation, "the usual handling of the intercept" is employed. This means that for the methods which do not take constraints, the intercept is included in the model while for the methods which do take constraints, the intercept is not included in the model. While this distinction will make it harder to understand why a particular method is performing better or worse than a method which handles the intercept differently, the results may be more useful in that the results reflect how one would actually employ each of the models in practice.


