Handling Factors in Formulas pt 2
In a recent blog post we discussed the process for reading in variables correctly. The gist was this:
If you want your variable treated as a factor (i.e., a categorical variable) then ensure that the values have letters.
This is still good advice. But an ongoing (note: CRAN is closed for the holidays so the updates are taking a while) update to Mighty Metrika tools will have another way to make sure your variables are being handled correctly. This blog will give a basic overview on using this new method. Other blogs posts which will drop within the next few weeks will also feature this new method.
First, let's use mmirestriktor to read in the data_f_grpnum.csv file which gave us issues in the Handling Factors in Formulas.
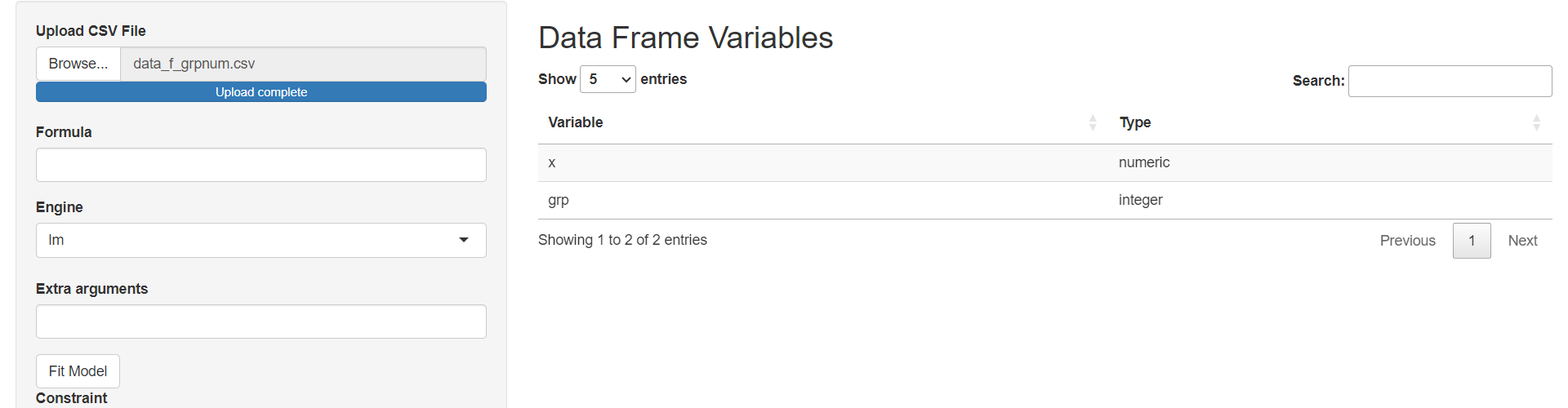
As in the previous blog post, notice that the grp variable has the type integer when we know that we want type factor. Before, this meant that we would need to refresh the app, ensure that all the values have a letter (i.e., g1, g2, g3 instead of 1, 2, 3), and re-import the data. Now you can fix the issue by:
- Double click 'integer' for the grp row
- Replace 'integer' by 'factor'
- Click in the white space anywhere beneath the table
Now you should see the following:
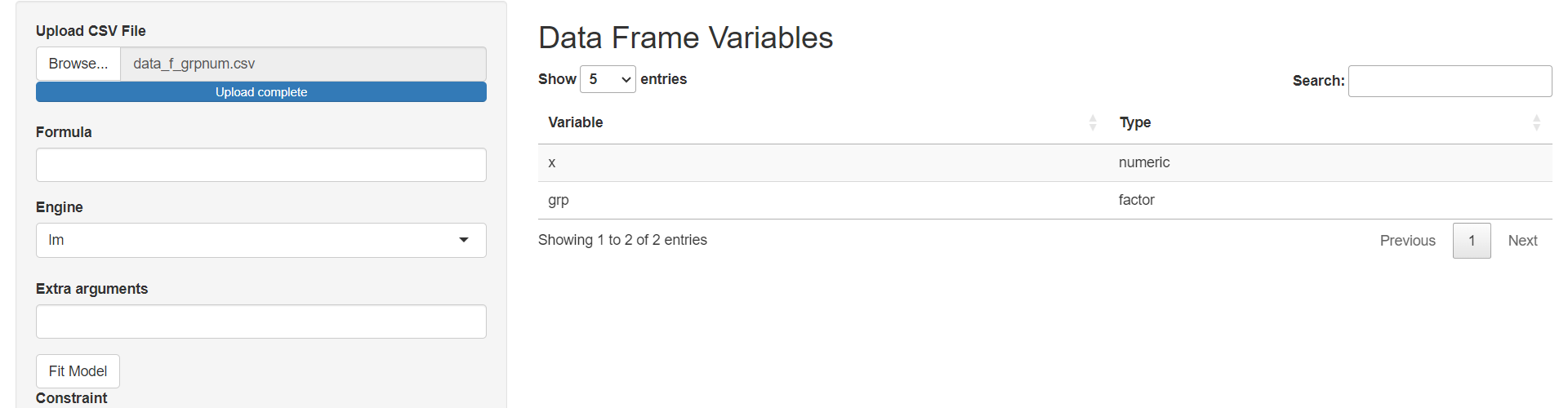
Now you can continue the analysis with the correct variable types.
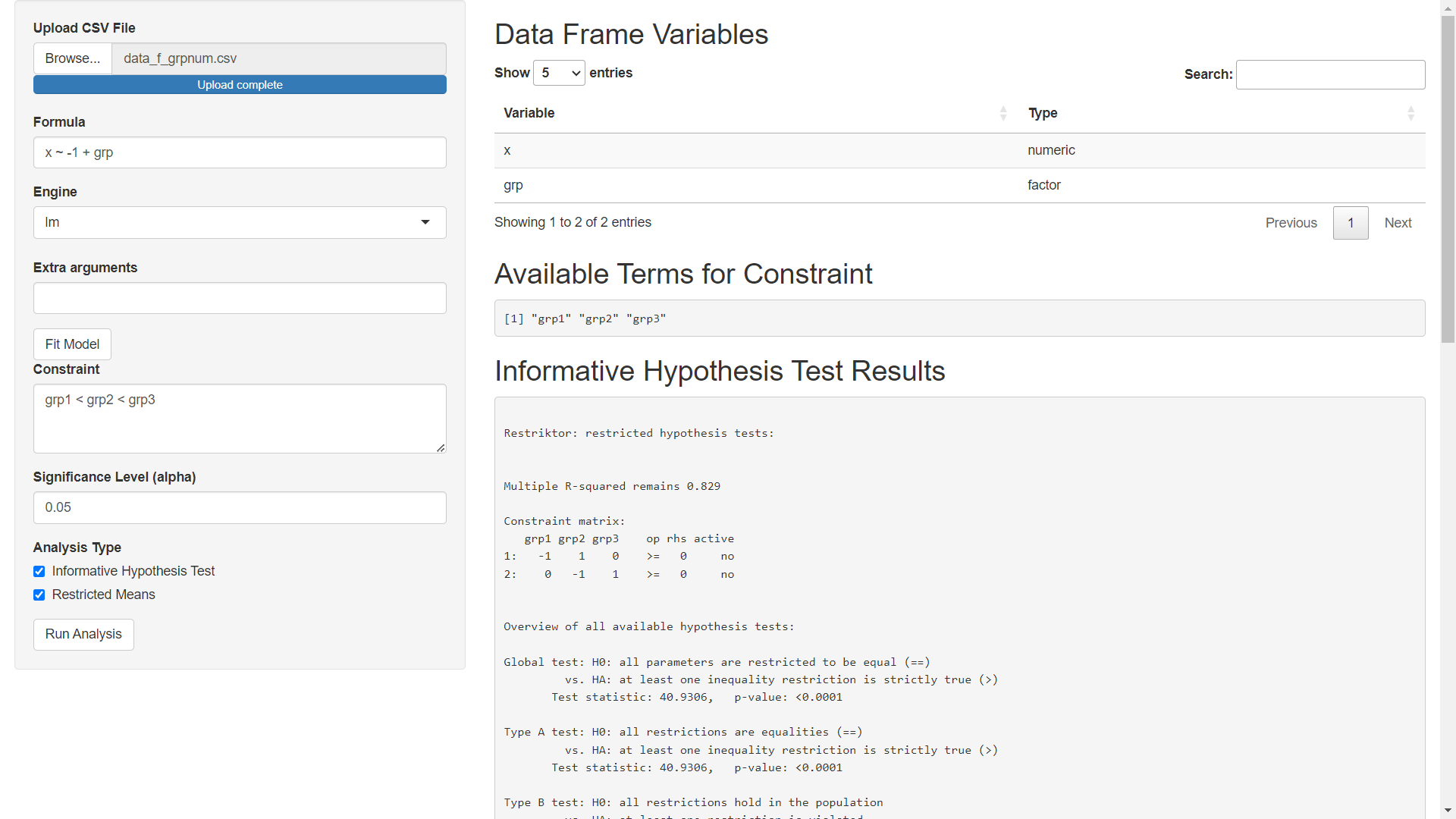
I am hoping that this will make the app easier to use. However, the process still needs a few major fixes. For example, look what happens when you accidently enter the type wrong. Instead of "factor" we accidently enter "fctor":
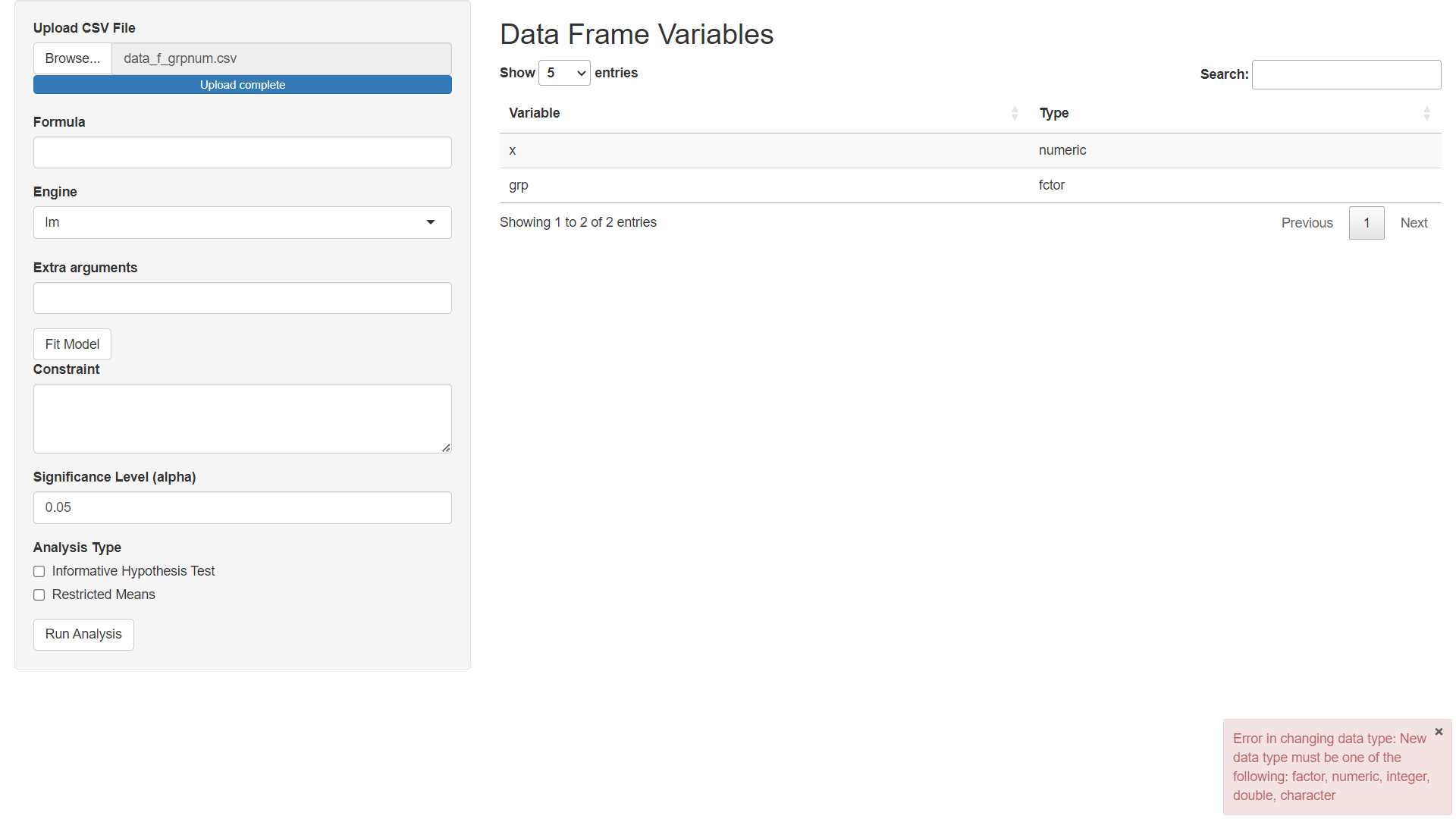
Notice that we get an error in the bottom right hand corner alerting us that we made a mistake. This should help us understand that we did something wrong and that we should not continue without correcting the mistake. However, if we are rushing or absent-minded, then we might accidently continue and get unfortunate results.
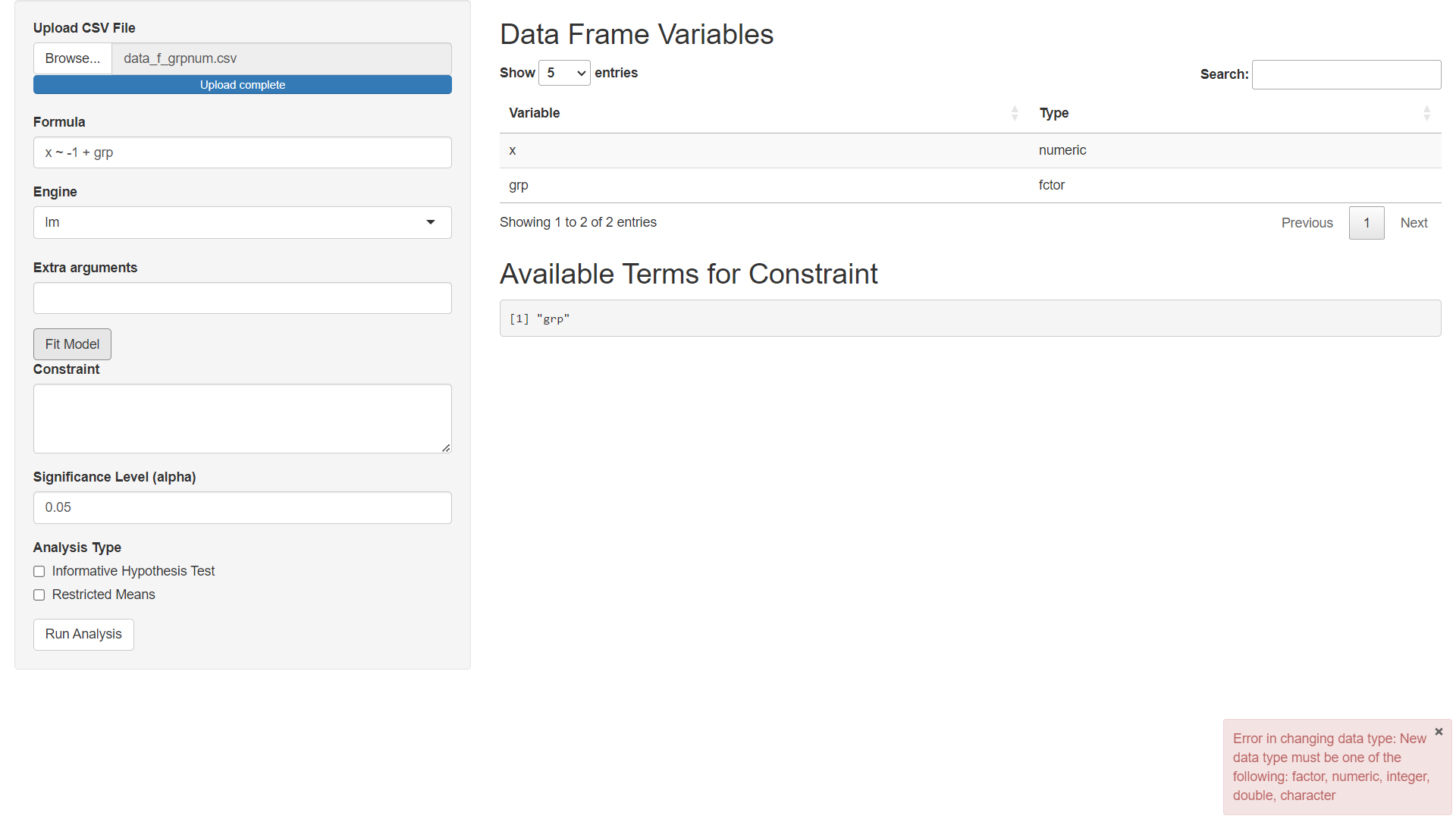
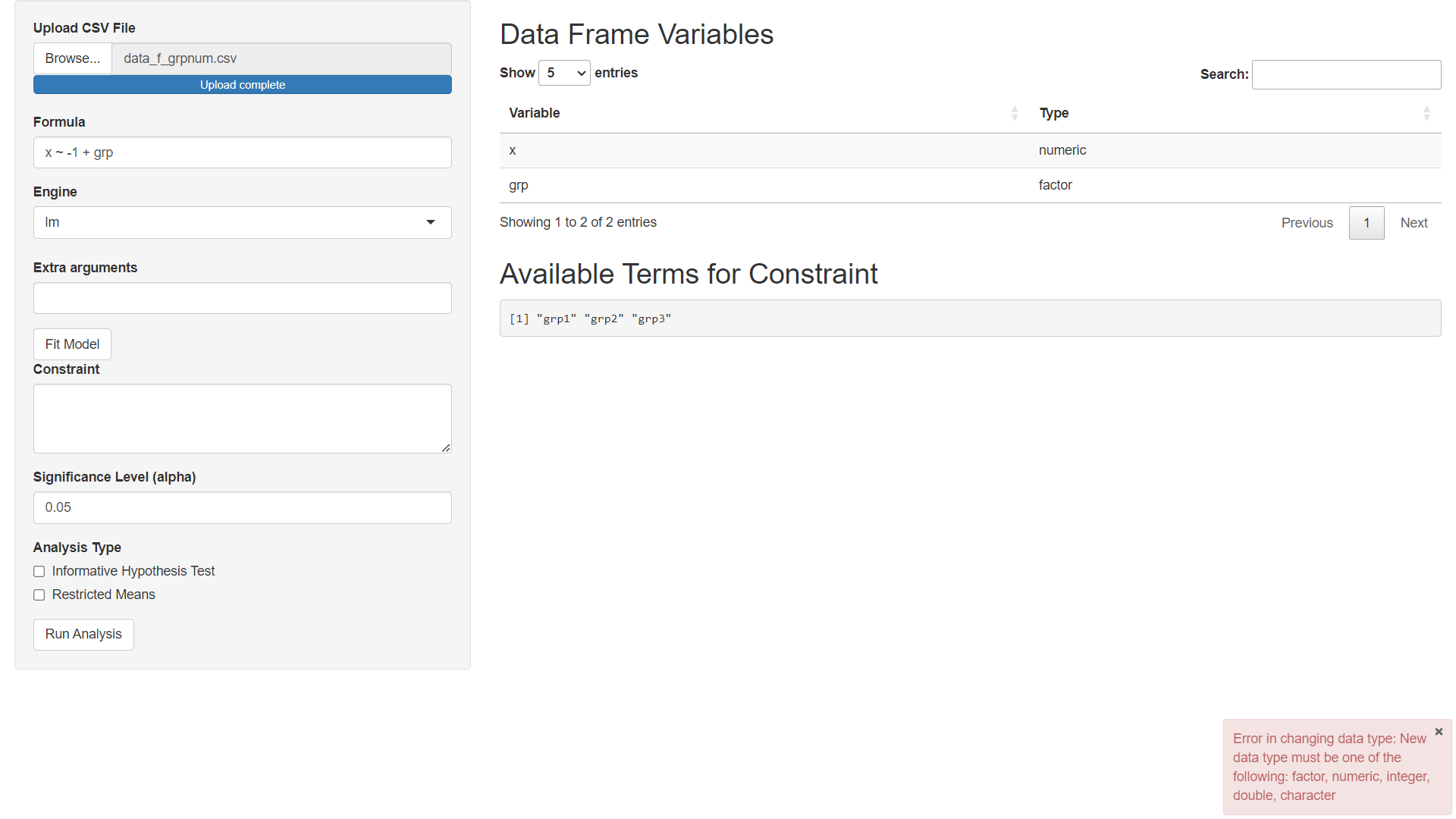
Notice that we cannot set up constraints based on the groups we expect to see since our data was not processed as a factor. We can fix this by:
- Going back up to the table and editing the type
- Click Fit Model again
Now just delete the error flag (I left it there for didactic purposes but remove it whenever you like) and finish the analysis.
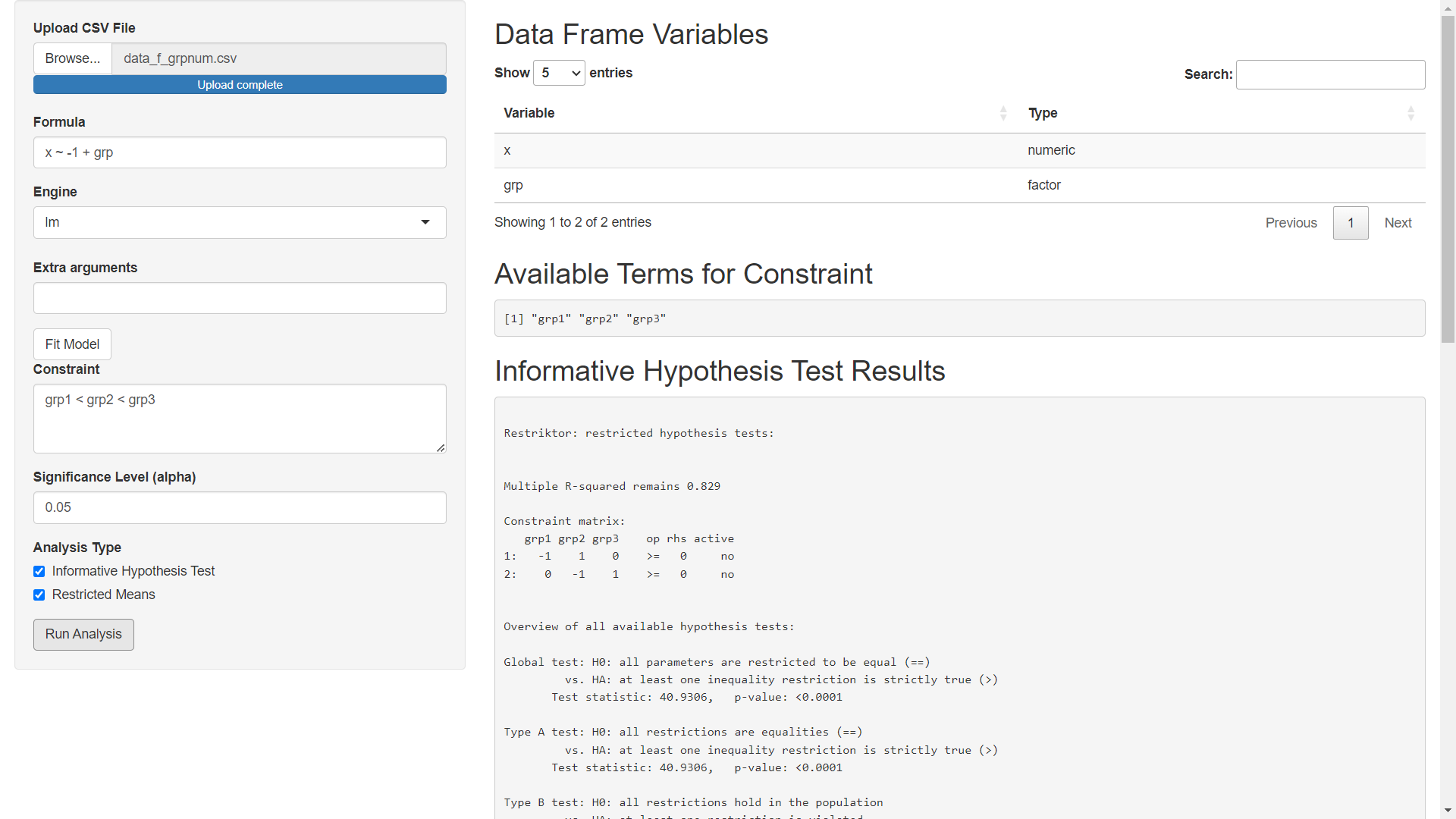
The process is not so pretty, but I believe it is better than before. I will make the same update to mmibain as soon as CRAN gets back from vacation. Blog posts with examples of the process will be posted soon too.


